Transforming legacy C code into EM
CoreMark® has emerged as the premier industry benchmark for measuring CPU performance within embedded systems. Managed through EEMBC , virtually every MCU vendor has certified and published CoreMark scores for a broad portfolio of their processors. Running the benchmark code also serves as a "typical workload" used when characterizing active power consumption [ μW / Mhz ] of a particular MCU.
The workload introduced by CoreMark encompasses four algorithms reflecting the variety of software functions often implemented within embedded application programs:
| list processing | find and remove elements, generalized sorting |
| matrix manipulation | add and multiply by a scalar, vector, or matrix |
| state machine | scan a string for a variety of numeric formats |
| cyclic redundancy check | checksum over a sequence of 16 / 32-bit values |
Besides adding to the workload, CoreMark uses algorithm to validate the final results of running the benchmark program – comparing a checksum over the list elements used in algorithm against an expected value. CoreMark also checksums the matrix data produced by algorithm as well as the state machine transitions encountered by algorithm .
You'll find the CoreMark sources on GitHub, together with instructions for building / running the benchmark program. To ensure the integrity of the benchmark, you cannot modify any of its (portable) C source files – with the exception of core_portme.[ch], used to adapt CoreMark to a particular hardware platform.
Needless to say, your choice of C compiler along with specific options for controlling program optimization remain on the table. While primarily intended for comparing different MCUs, CoreMark also provides a known codebase useful for "apples-to-apples" comparisons between different compilers [GCC, IAR, Keil, LLVM] targeting the same MCU.
CoreMark – a "typical" C program in more ways than one
We sense that very few software practitioners have actually studied the CoreMark source files themselves. As long as "someone else" can actually port / build / run the benchmark on the MCU of interest, good enough !!
In our humble opinion, the CoreMark sources would not serve as the best textbook example of well-crafted C code: insufficent separation of concerns, excessive coupling among compilation units, plus other deficiencies.
Said another way, CoreMark typifies the design / implementation of much of the legacy embedded C code we've encountered for decades within industry and academia alike. But therein lies an opportunity to showcase EM.
CoreMark ⇒ EM•Mark
In reality, none of the official CoreMark sources (written in C) will survive their transformation into EM•Mark – a new codebase (re-)written entirely in EM. At the same time, applying the same CoreMark algorithms to the same input data must yield the same results in EM.
The input data used by EM•Mark (like CoreMark) ultimately derives from a handful of seed variables, statically-initialized with prescribed values. Declared volatile in EM as well as C, the integrity of the benchmark requires that the underlying compiler cannot know the initial values of these seed variables and potentially perform overly-aggressive code optimizations.
At the same time, the CoreMark sources do make use of C preprocessor #define directives to efficiently propogate constants and small (inline) functions during compilation. EM•Mark not only achieves the same effect automatically via whole-program optimization, but also leverages the full power of EM meta-programming to initialize internal data structures at build-time – resulting in a far-more compact program image at run-time.
If necessary, review the material on program configuration and compilation to fully appreciate the opportunities that EM affords for build-time optimization.
High-level design
The EM•Mark sources (found in the em.coremark package within the em.bench bundle) consist of ten EM modules and two EM interfaces, organized as follows:
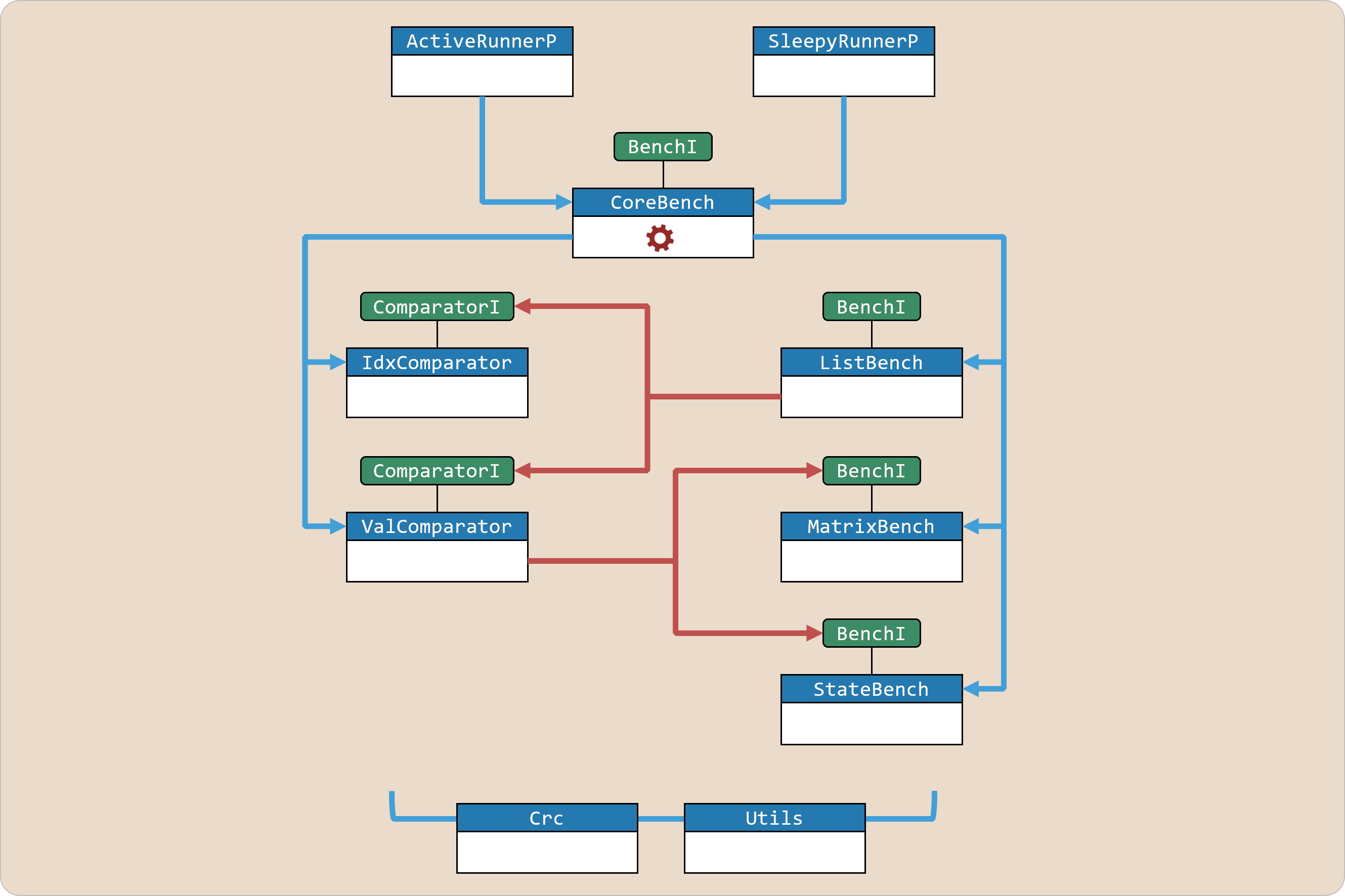
The ActiveRunnerP and SleepyRunnerP programs on top of this hierarchy both execute the same core benchmark algorithms, albeit in two very different contexts:
ActiveRunnerP performs multiple benchmark iterations, much like the legacy CoreMark program
SleepyRunnerP performs a single benchmark iteration, awakening every second from deep-sleep
The CoreBench module (imported by both of these programs) coordinates both configuration as well as execution of the list processing, matrix manipulation, and state machine algorithms; we'll have more to say about its implementation in a little while.
To capture behavioral commonality between CoreBench and the algorithm modules it uses internally [ ListBench, MatrixBench, StateBench ], our EM•Mark design introduces the abstract em.coremark/BenchAlgI interface:
| em.coremark/BenchAlgI.em | |
|---|---|
Of the handful of functions specified by this interface, two of these play a central role in the implementation of each benchmark algorithm:
BenchAlgI.setup, which initializes the algorithm's input data using volatile seed variables
BenchAlgI.run, which executes one pass of the benchmark algorithm and returns a CRC value
Taking a quick peek inside CoreBench, you'll notice how this module's implementation of the BenchI interface simply delegates to the other algorithm modules – which in turn implement the same interface:
CoreBench also uses public get / set functions provided by the Utils module to fetch / store designated CRC and seed values.
more code ahead – free free to scroll down to the Summary
Each of the benchmark algorithms will call the Crc.add16 or Crc.addU32 functions to fold a new data value into a particular checksum. Looking at the implementation of the Crc module, both of these function definitions ultimately call Crc.update – a private function that effectively mimics the crcu8 routine found in the legacy CoreMark source code:
| core_util.c | |
|---|---|
Finally, CoreBench defines a pair of config params [ TOTAL_DATA_SIZE, NUM_ALGS ] used to bind the BenchAlgI.memSize parameter associated with the other algorithms; refer to CoreBench.em$configure defined here for further details. Initialized to values tracking the legacy CoreMark code, CoreBench assigns ⌊2000/3⌋ ≡ 666 bytes per algorithm.(1)
- We'll have more to say about
CoreBench.em$configureafter we explore the three benchmark algorithms in more detail.
Matrix manipulation
Pivoting to the simplest of the three benchmark algorithms administered by CoreBench, the MatrixBench module implements each (public) function specified by the BenchAlgI interface; and most of the MatrixBench private functions defined inside the module [ addVal, mulVec, clip, etc ] correspond to legacy C functions / macros found in core_matrix.c .
Internally, MatrixBench operates upon three matrices [ matA, matB, matC ] dimensioned at build-time by the module's em$construct function – which uses the BenchI.memSize parameter (bound previously in CoreBench.em$configure) when calculating a value for dimN:
| em.coremark/MatrixBench.em [exc] | |
|---|---|
| em.coremark/MatrixBench.em [exc] | |
|---|---|
The MatrixBench.setup function initializes "input" matrices [ matA, matB ] at run-time, using values derived from two of the volatile seed variables prescribed by legacy CoreMark:
MatrixBench.run finally executes the benchmark algorithm itself – calling a sequence of private matrix manipulation functions and then returning a checksum that captures intermediate results of these operations:
Once again, the [EM] implementations of private functions like addVal and mulMat track their [C] counterparts found in the CoreMark core_matrix.c source file.
State machine
The StateBench module – which also conforms to the BenchAlgI interface – scans an internal array [ memBuf ] for text matching a variety of numeric formats. Similar to what we've seen in MatrixBench, the build-time em$construct function sizes memBuf as well as initializes some private config parameters used as run-time constants:
| em.coremark/StateBench.em [exc] | |
|---|---|
The StateBench.setup function uses the xxxPat and xxxPatLen config parameters in combination with a local seed variable to initializing the memBuf characters at run-time:
Details aside, StateBench.run calls a private scan function which in turn drives the algorithm's state machine; run also calls a private scramble function to "corrupt" memBuf contents ahead of the next scanning cycle:
The crc returned by StateBench.run effectively summarizes the number of transitory and finals states encountered when scanning.
even more code ahead – free free to scroll down to the Summary
List processing
Unlike its peer benchmark algorithms, the ListBench module introduces some new design elements into the EM•Mark hierarchy depicted earlier:
the ComparatorI abstraction, used by ListBench to generalize its internal implementation of list sorting through a function-valued parameter that compares element values
the ValComparator module, an implementation of ComparatorI which invokes the other benchmark algorithms (through a proxy) in a data-dependent fashion
The ComparatorI interface names just a single function [ compare ] ; the ListBench module in turn specifies the signature of this function through a public type [ Comparator ] : (1)
- a design-pattern similar to a Java
@FunctionalInterfaceannotation or a C#delegateobject
| em.coremark/ComparatorI.em | |
|---|---|
| em.coremark/ListBench.em [exc] | |
|---|---|
CoreBench.em$configure (which we'll examine shortly) performs build-time binding of conformant Comparator functions to the pair of ListBench config parameters declared above. But first, let's look at some private declarations within the ListBench module:
The Elem struct supports the conventional representation of a singly-linked list, with the ListBench private functions manipulating references to objects of this type. The maxElems parameter effectively sizes the pool of Elem objects, while the curHead variable references a particular Elem object that presently anchors the list.
Similar to the other BenchAlgI modules we've seen, ListBench cannot fully initialize its internal data structures until setup fetches a volatile seed at run-time. Nevertheless, we still can perform a sizeable amount of build-time initialization within em$construct:
| em.coremark/ListBench.em [exc] | |
|---|---|
Like all EM config params, maxElems behaves like a var at build-time but like a const at run-time; and the value assigned by em$construct will itself depend on other build-time parameters and variables [ itemSize, memSize ]. In theory, initialization of maxElem could have occurred at run-time – and with EM code that looks virtually identical to what we see here.
But by executing this EM code at build-time , we'll enjoy higher-levels of performance at run-time .
Taking this facet of EM one step further,(1)em$construct "wires up" a singly-linked chain of newly allocated / initialized Elem objects anchored by the curHead variable – a programming idiom you've learned in Data Structures 101 . Notice how each Elem.data field similarly references a newly-allocated (but uninitialized ) Data object.
- that the EM language serves as its own meta-language
Turning now to ListBench.setup, the pseudo-random values assigned to each element's e.data.val and e.data.idx fields originate with one of the volatile seed variables prescribed by CoreMark. Before returning, the private sort function (which we'll visit shortly) re-orders the list elements by comparing their e.data.idx fields:
Finally, the following implementation of ListBench.run calls many private functions [ find, remove, reverse, … ] to continually rearrange the list elements; ListBench.run also uses another volatile seed as well as calls sort with two different Comparator functions:
Refer to ListBench for the definitions of the internal functions called by ListBench.run .
Generalized sorting
As already illustrated, the ListBench.sort accepts a cmp argument of type Comparator – invoked when merging Data objects from a pair of sorted sub-lists: (1)
- The implementation seen here (including the inline comments) mimics the
core_list_mergesortfunction found in the legacycore_list_join.csource file.
Looking first at the IdxComparator module, you couldn't imagine a simpler implementation of its ComparatorI.compare function – which returns the signed difference of the idx fields after scrambling the val fields:
| em.coremark/IdxComparator.em [exc] | |
|---|---|
Turning now to the ValComparator module, you couldn't imagine a more convoluted implementation of ComparatorI.compare – which returns the signed difference of values computed by the private calc function: (1)
- the twin of
calc_funcfound in the legacycore_list_join.csource file
Besides scrambling the contents of a val field reference passed as its argument, calc actually runs other benchmark algorithms via a pair of BenchAlgI proxies [ Bench0, Bench1 ] .
Benchmark configuration
Having visited most of the individual modules found in the EM•Mark design hierarchy, let's return to CoreBench and review its build-time configuration functions:
In addition to calculating and assigning the memSize config parameter for each of the benchmarks, CoreBench.em$configure binds a pair of Comparator functions to ListBench as well as binds the StateBench and MatrixBench modules to the ValComparator proxies.
CoreBench.em$construct completes build-time configuration by binding a prescribed set of values to the volatile seed variables accessed at run-time by the individual benchmarks.
Summary and next steps
Whether you've arrived here by studying (or skipping !!) all of that EM code, let's summarize some key takeaways from the exercise of transforming CoreMark into EM•Mark :
The CoreMark source code – written in C with "plenty of room for improvement" – typifies much of the legacy software targeting resource-constrained MCUs.
The high-level design of EM•Mark (depicted here) showcases many aspects of the EM langage – separation of concerns, client-supplier decoupling, build-time configuration, etc.
The ActiveRunnerP and SleepyRunnerP programs can run on any MCU for which an em$distro package exists – making EM•Mark ideal for benchmarking MCU performance.
Besides embodying a higher-level of programming, EM•Mark also outperforms legacy CoreMark.
To prove our claim about programming in EM, let's move on to the EM•Mark results and allow the numbers to speak for themselves.